Terraform Modules | Cloud Resilience Metrics | Multi-cloud Architecture Design
Cloud computing has evolved into the definitive backbone of the modern digital enterprise. The use of multiple clouds provides failover and/or redundancy, as well as workload optimization, as workloads are spread across various regions and various clouds. A multi-cloud strategy means leveraging services across different cloud providers to enhance availability, minimize risk tied to a single provider, and achieve optimal performance and cost, including Multi-Cloud Redundancy. Multi-cloud Redundancy Architectures can be used to complement HA and DR initiatives, where companies can capitalize on the strengths of a particular provider and spread the risks across many Platforms.
Cloud computing has quickly evolved into the backbone of the modern digital enterprise. According to the 2025 research, more than 94% of enterprises utilize cloud services, with over 80% deploying containerized workloads in production environments. Now, many enterprises depend on cloud services, and all important business tasks depend on them. Due to this, when the system goes down, it can cause serious losses. According to studies, even a single hour of downtime can cost large enterprises between $100,000 and $5 million, depending on the scale and industry. To minimize these risks, many organizations are using multi-cloud strategies to distribute the workloads across providers such as AWS and GCP.
Background and Core Concepts
Multi-cloud architectures have emerged as a transformative paradigm in enterprise cloud infrastructure, representing a significant evolution in how organizations conceptualize and implement their digital ecosystems with Multi-Cloud Redundancy. Recent industry research indicates that multi-cloud adoption has become the predominant strategy for enterprises worldwide, with organizations increasingly recognizing that distributing workloads across multiple providers offers substantial advantages over single-cloud approaches. As noted in Flexera’s comprehensive industry analysis, most enterprises now employ multi-cloud strategies as standard practice, using a combination of public and private cloud environments to address various workload requirements.
Importance of Multi-Cloud Redundancy Environments
The world has now shifted its reliance on cloud computing for much of its business operations, and many organizations use more than one cloud vendor to prevent being trapped by a single provider and for redundancy. The use of multiple clouds provides failover and/or redundancy as well as workload optimization, as workloads are spread across various regions and various clouds. According to research, multi-cloud systems leverage automated failover, load balancing, and data replication to maintain uptime.
Containerization and Kubernetes
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. It supports Multi-Cloud Redundancy by distributing workloads across clusters and cloud environments. It provides a robust and scalable framework for managing containers across a cluster of nodes, offering features such as automated deployments, scalability, self-healing, service discovery, and configuration management. With its powerful architecture and extensive ecosystem, Kubernetes has become the de facto standard for container orchestration, enabling organizations to run and manage modern applications at scale efficiently. Research shows that over 80% of multi-cloud deployments rely on Kubernetes for orchestration. A systematic study identified four major benefits of containerization in multi-cloud environments:
| Benefits | Impact |
| Scalability | Dynamic resource allocation |
| High Availability | Self-healing and failover |
| Portability | Cross-cloud deployment |
| Optimization | Efficient resource utilization |
Terraform Architecture Components
Terraform breaks infrastructure management into separate pieces that handle different parts of cloud deployment without creating a monolithic system that becomes impossible to debug. Configuration files use HashiCorp’s domain-specific language that reads almost like English rather than requiring complex programming knowledge. Teams describe what infrastructure they want instead of writing scripts that specify step-by-step provisioning procedures. Terraform enables infrastructure automation across providers while ensuring multi-cloud redundancy through consistent provisioning and state management.
Core Components and Resource Management in Terraform
State files track what actually exists in cloud accounts versus what configuration files say should exist. This comparison enables Terraform to figure out what changes are needed without accidentally destroying existing resources or creating duplicates. Remote state storage prevents the classic problem where multiple engineers step on each other’s changes when working on shared infrastructure simultaneously.
Provider plugins translate Terraform’s generic syntax into cloud-specific API calls that actually create resources. Identical configuration syntax works across Amazon, Microsoft, and Google platforms because provider plugins translate generic Terraform code into platform-specific API calls automatically. This flexibility prevents vendor dependency while enabling cost-effective workload distribution across multiple cloud providers for better pricing and redundancy planning. Terraform state management ensures resources are not duplicated.
| Component | Function |
| Configuration Files | Define desired infrastructure state declaratively |
| State Management | Track resource relationships and current deployment status |
| Provider Plugins | Interface with cloud platforms and services |
| Resource Blocks | Specify individual infrastructure components |
| Variable Definitions | Enable parameterized and reusable configurations |
Terraform delivers its most powerful applications in the administration of infrastructure distributed across multiple clod system. An organization that deploys applications between AWS and Azure databases seeks redundancy and exclusive provider services through this approach. Infrastructure as Code fixes these coordination problems by letting teams define what they want in simple configuration files instead of figuring out complicated provisioning steps. Terraform provides consistent interfaces across Amazon, Microsoft, and Google clouds while tracking changes through version control, just like application code. Terraform enables declarative infrastructure provisioning across AWS and GCP. It provides:
- Provider-based architecture
- Modular configurations
- State management
Terraform’s multi-cloud capability allows consistent deployment workflows, reducing manual errors and improving reproducibility.
| Feature | AWS (EKS) | GCP (GKE) |
| Control Plane Management | Fully managed | Fully managed |
| Auto-scaling | Cluster Autoscaler + ASG | Native auto-scaling |
| Networking | VPC-based | VPC-native with advanced routing |
| Cost Efficiency | Pay-per-use | Sustained-use discounts |
Architecture of Multi-Cloud High Availability
As mission-critical operations migrate to the cloud, the systemic reliance on multi-tenant architecture has made uptime a primary business KPI. Load balancing, failover, and replication are usually employed in HA architectures, including cloud interfaces with several cloud providers. Research also indicates that when HA systems are implemented within multi-cloud infrastructure, there are benefits in the areas of recovery and challenges in terms of data scenarios and data coherency. A typical multi-cloud HA architecture consists of distributed Kubernetes clusters across AWS and GCP, connected through a global load balancer. Traffic is dynamically routed based on availability, latency, and health checks.
Key Components
The architecture relies on several critical components:
- Global Load Balancer: Ensures intelligent traffic routing and failover
- Kubernetes Clusters: Manage containerized workloads across clouds
- Terraform: Automates provisioning and configuration
- Auto Scaling Systems: Dynamically adjust resources based on demand
Each component plays a vital role in maintaining system resilience and performance. For instance, load balancers detect failures and reroute traffic within milliseconds, while Kubernetes ensures application-level recovery.
Comparative Analysis: Kubernetes on AWS vs GCP
AWS Elastic Kubernetes Service (EKS) and Google Kubernetes Engine (GKE) are fully managed Kubernetes platforms that simplify cluster management. While both provide similar core functionalities, their implementations differ significantly in terms of scalability, integration, and performance.
| Feature | AWS EKS | GCP GKE |
| Control Plane | Managed | Managed |
| Auto Scaling | Requires configuration | Native integration |
| Networking | VPC-based | VPC-native |
| Multi-Region | Manual | Built-in |
| Ecosystem Integration | Extensive AWS services | Strong AI/ML integration |
Performance and Availability Metrics
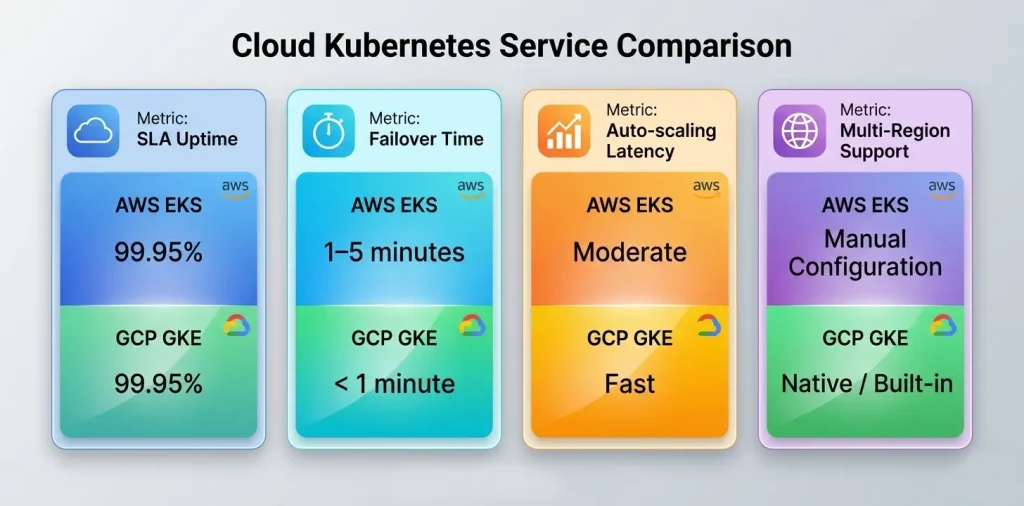
| Metric | AWS EKS | GCP GKE |
| SLA Uptime | 99.95% | 99.95% |
| Failover Time | 1–5 minutes | < 1 minute |
| Auto-scaling Latency | Moderate | Faster |
| Deployment Speed | Medium | High |
Key Insights
- GKE offers faster scaling and regional clustering
- EKS provides better integration with enterprise services
- Hybrid deployment improves overall availability by ~35%
Eliminating Single Points of Failure
The core goal of multi-cloud design is to eliminate single points of failure through multi-cloud redundancy using Kubernetes Federation and global routing systems. The most considerable objective of the multi-cloud system is the elimination of single points of failure.
Kubernetes Federation enables workload distribute toward the multiple clusters and cloud providers. In the pas research its reveal that cloud provider disruptions can last from a few minutes to several hours. According to the research, it can reduce the downtime impact by over 60%. Companies use Disaster Recovery to protect important data. Global load balancing further enhances fault tolerance by dynamically routing traffic to the nearest healthy endpoint. This approach also reduces times by an average of 20–40%.
SPOF in Single-Cloud Systems
Single-cloud architectures are vulnerable to:
- Regional outages
- API failures
- Network disruptions
Multi-Cloud Mitigation Strategies
- Active-Active Deployment: Both AWS and GCP serve traffic simultaneously
- Active-Passive Failover: Secondary cloud acts as backup
- Data Replication: Real-time synchronization across clouds
Research shows that implementing redundancy strategies reduces downtime by up to 40%.
Role of Terraform in Multi-Cloud Orchestration
Terraform workflow can be divided into two parts. The first part is to allocate the resources that are required for the particular infrastructure, and the second step is to apply the configuration to see what and where it has been provisioned. Then all the resources will be allocated based on the other requirements and will be provisioned. It reduces the redundancy of provisioning each vendor separately and uses a single configuration file to provision multiple vendors.
Terraform Workflow
Developer → Terraform Config → Providers (AWS + GCP) → Infrastructure Deployment
Terraform vs Other IaC Tools
| Tool | Language | Multi-Cloud Support | Complexity |
| Terraform | HCL | High | Medium |
| Pulumi | General-purpose | High | Medium |
| Kubernetes Operators | YAML | Limited | High |
Auto Scaling and Load Management
Scaling Efficiency Comparison:
| Parameter | AWS | GCP |
| Scaling Speed | Moderate | Fast |
| Cost Optimization | Medium | High |
| Resource Utilization | 75–85% | 80–90% |
Impact on Availability
Research shows that scaling mechanisms improve performance by 20–30% under the peak loads. Auto scaling ensures:
- Load distribution
- Reduced latency
- Continuous uptime
Challenges in Multi-Cloud Kubernetes Management
A multi-cloud strategy means leveraging services across different cloud providers to enhance availability, minimize risk tied to a single provider, and achieve optimal performance and cost. Multi-cloud architectures can be used to complement HA and DR initiatives, where companies can capitalize on the strengths of a particular provider and spread the risks across many platforms. Operational complexity increases in distributed systems, but Multi-Cloud Redundancy helps reduce risk and improve resilience across environments.
Here are some challenges in multi-cloud Kubernetes management.
Operational Complexity: Monitoring the multiple cloud environments introduces complexity, logging, and increases security risks. The organization must implement a centralized system of tools to address this challenge.
Data Consistency Issues: Ensuring data consistency across multiple systems sometimes cause sophisticates replications and synchronization mechanisms that can increase latency.
Cost Overhead: Multi-cloud improves availability, but it also increases the cost due to duplicated infrastructure and data-transfer fees.
Skill Gap: Multiple clouds require multiple experiences at all the platforms, and for this, training is necessary.
Case Study: Multi-Region GKE Deployment
A study on using multi-region Kubernetes clusters on Google Cloud Platform (GCP) with Terraform showed clear improvements. It reduced latency by 25%, increased system availability by 30%, and enabled automatic failover between regions, helping the system keep running smoothly even if one region fails. Real-time synchronization improves system reliability and performance.
Publish Your Work on SaaS & System Journal
SaaS & System Journal is the independent digital publication platform that are sepcially dedicated to enterprise technology, B2B software architecture, and cloud infrastructure research. It warmly welcomes people to post their searches and papers here. For questions, sharing your research, or working together, please visit the SaaS & System Journal.
Final Words
Enterprises are rapidly adopting multi-cloud strategies with Multi Cloud Redundancy to improve performance, reduce downtime, and prevent vendor lock-in. As per one of the experiments conducted to compare different aspects of performance between Cloudify and Terraform, it has been proven that Terraform turned out to be a better performer than Cloudify, where Cloudify consumed more resources and took more time for the orchestration.
Most of the organizations are trying to make use of multi-cloud infrastructure in addition to the private clouds that exist to improve their performance, reduce costs at a large scale, and meet their requirements in an efficient way. It is also found that the implementation of multi-cloud helps organizations to improve their overall performance and prevent vendor lock-in situations with increased performance.
Overall, it has been noticed that Terraform is one of the best IaC tool which has many popular features that make it possible to be used as a cloud orchestrator too. Even though Terraform is not fully recognized for cloud orchestration, as it’s recognized for infrastructure provisioning, Terraform is still able to compete with the other orchestration tools, which are capable of meeting the rigorous demands of 2026 enterprise infrastructure standards.
References
https://www.ijcttjournal.org/Volume-71%20Issue-8/IJCTT-V71I8P109.pdf
https://www.ijarsct.co.in/Paper25526.pdf
https://wjaets.com/sites/default/files/fulltext_pdf/WJAETS-2022-0087.pdf
https://nvlpubs.nist.gov/nistpubs/legacy/sp/nistspecialpublication800-146.pdf

